二元分类
尽管对于二元分类问题,逻辑回归也可以起到作用,但是我们还是要介绍一些其他的模型。比如PLA
Percetron Learning Algorithm
PLA用于解决对于二维或者多维的线性可分的问题,最终将问题分为两类—是或者不是。其中标签为{-1, 1}
我们使用一种感知器模型(Percetron), 逻辑回归和线性回归都是类似感知器模型的。在PLA中,感知器模型为:

经过变换之后,将threshold当作x0,那么我们就得到了我们的感知器模型
\[h(x) = sign(\sum_{i=0}^dw_ix_i) = sign(w^Tx)\]演算法
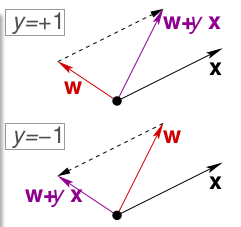
在PLA中,我们使用向量的方法,对于一个向量x,一个向量w,如果两者角度大于90度,那么其结果就是负,如果小于90度,则结果为正,因此,我们就以通过修改$w$和$x$的角度来逐渐逼近答案。
需要注意的是,分界线是垂直于w的。
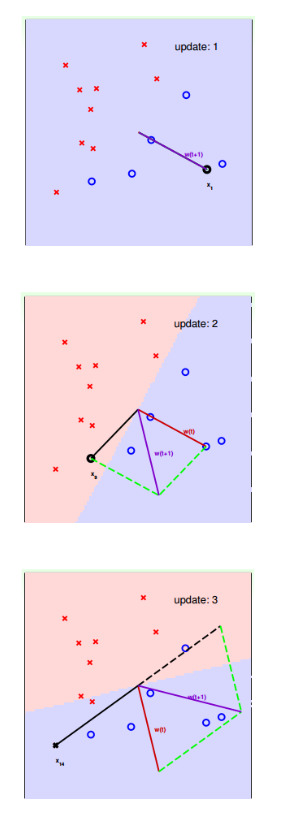
我们只需要逐次迭代就可以最终的到好的结果

部分例子如下,如果继续更新,我们最终会得到较好的结果
Packet Algorithm
对于线性可分的问题,PLA是可以停下来并正确分类的,但是对于非线性问题,PLA并不一定停下来,所以我们可以把条件放松,选择错误点最少时的权重w。
一个修改的算法就是Packet Algorithm,首先初始化$w_0$,计算这条初始化的直线中,分类错误点的个数,然后对错误点进行修正,得到一个新的w,计算其对应的分类错误的点的个数,并与之前的错误点的个数比较,如取较小点的直线作为我们当前选择的分类直线。之后,经过n次迭代,不断比较,选择最小的值保存。

Linear Models for Binary Classification
前面介绍的几种线性模型都有一个特点,就是都有样本特征x的加权运算,即:
\[s = w^Tx\]三种线性模型,分别是线性分类器,线性回归,逻辑回归。
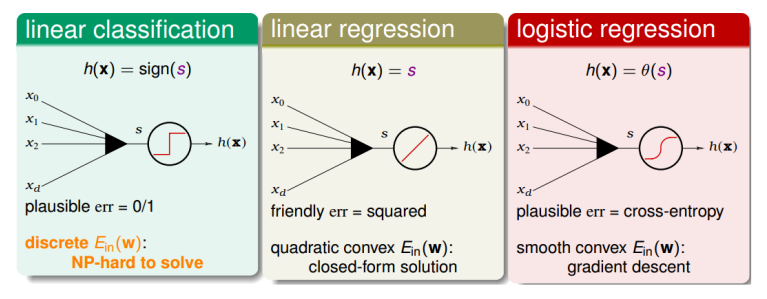
三者似乎有一些共同点,那么对于线性回归和逻辑回归能不能用于处理线性分类问题呢?
对于线性分类,他的error function可以写成:
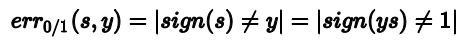
对于线性回归,他的error function可以写成
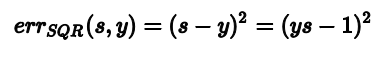
对于逻辑回归,它的error function为:
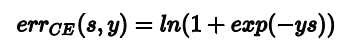
为了分析三者的区别,我们选择可视化他们,同时为了方便计算,我们将$err_{CE}(s, y)$进行换底, 这能保证$err_{sce}(s, y)$始终在$err_{0/1}$上面。

由图,我们可以得知:
\[E_{in}(w) \le E_{in}^{SCE}(w) = \frac{1}{ln2}E_{in}^{CE}(w)\\ E_{out}(w) \le E_{out}^{SCE}(w) = \frac{1}{ln2}E_{out}^{CE}(w)\]根据在机器学习可行性中提到的VC理论,我们可以知道
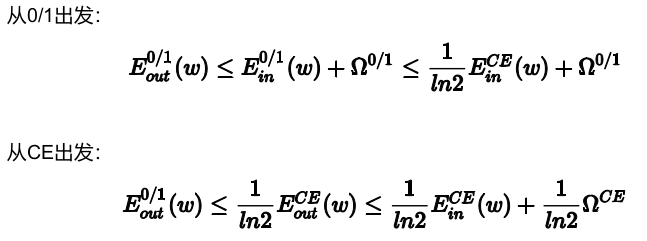
可见,$err_{0/1}$被限定在一个上届中,这个上届是由逻辑回归中的error function决定的,而线性回归也是线性分类的一个upper bound。综上,线性回归和逻辑回归也可以用来解决线性分类问题。
对于三种不同模型在解线性分类问题的优点和缺点。通常我们使用线性回归来初始化$w_0$,然后使用逻辑回归模型进行最优化解。

随机梯度下降(Stochastic Gradient Descent)
在逻辑回归问题中,使用的是批量梯度下降(Batch Gradient Descent)。每次迭代都要对N个点进行计算,时间复杂度为O(N)。而且如果数据过多,计算量也会有极大的增长。所以,我们有一种替代的思想,叫做随机梯度下降(SGD)。
随即梯度下降算法每次迭代只找到一个点,计算该点的梯度,作为下一步更新w的依据。这样就保证了每次迭代的计算量大大减小。最重要的是随即梯度下降算法是一个online算法。但是他的缺点是不够稳定,需要更多的迭代次数。
尽管样本的随机性会带来噪声,单次迭代上看,好像会对每一步找到正确梯度方向有影响,但是整体期望上看,与真是梯度的方向并不会有太大的区别。

所以对于逻辑回归的SGD,他的表达式为:
\[w_{t+1} \leftarrow w_t + \eta \theta(-y_nw_t^Tx_n)(y_nx_n)\]其中,一般迭代次数足够多,我们就可以终止了,对于$\eta$,要根据实际情况来定,一般取0.1。
多分类问题
OVA
一种解决思路就是计算某个点属于某类的概率,然后选择概率最大的那一类就可以了。
在实现这种方法时,我们先令某一类为正,其他三类为负,然后我们就可以得到这个正类的概率,然后选择另外一个为正类,逐次进行。
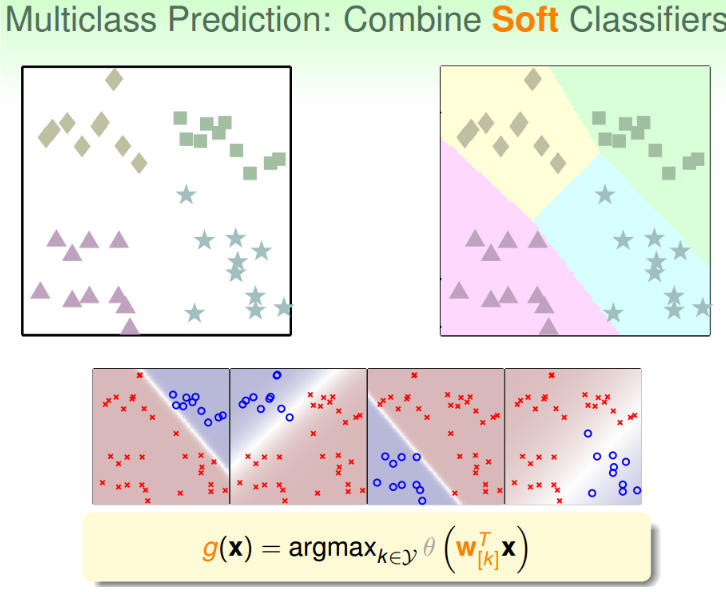
这种多分类的处理方式,称之为One-Versus-All(OVA) Decompostio,这种方法的优点是简单高效,可以使用逻辑回归模型来解决,缺点是如果数据类别很多时,那么每次二分类问题中,正类和负类数量差别就很大,数据不平衡,会影响分类效果。
其算法过程为:
OVO
当分类种类过多时,会导致分类效果不好,所以,在类别很多时,我们可以使用二元分类。基于二元分类的多分类问题与逻辑回归问题有些不同。
在算法过程中,我们每次只取两类进行二元分类,取值为{-1, 1}。加入k=4,那么总共需要$C_4^2 = 6$次二元分类。当我们得到六个分类器时,如果重新来了一个样本,我们就可以使用这六个分类器进行投票,投票最多的那个就是该样本的类别。
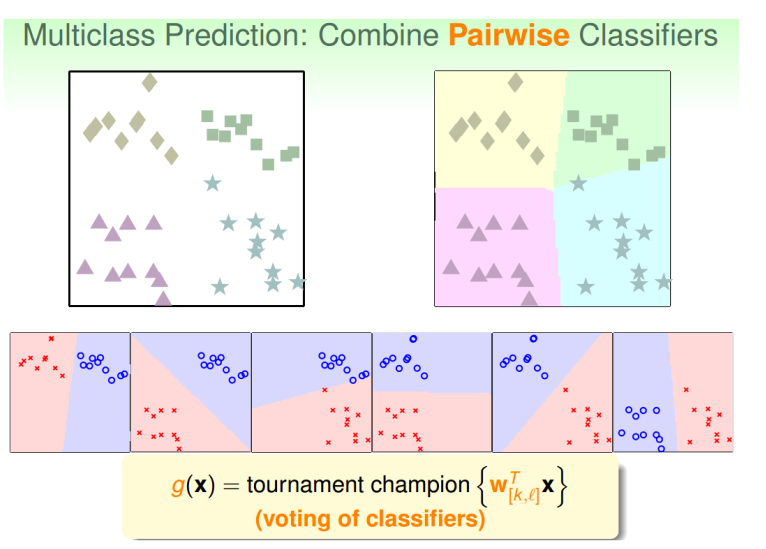
这中多分类问题叫做One-Versus-One(OVO)。这种方法的有点更加高效,尽管需要分类次数增多了,但是每次只需要比较两个类。而且一般不会出现数据不平衡的情况。缺点是需要分类的次数多,时间复杂度和空间复杂度都比较高。
