特征描述符
当我们进行完角点检测后,我们就可以在不同的图片中寻找相同的特征了。
但是不同的图像会存在平移,旋转,光照等种种情况,我们必须保证,这些检测的特征在不同的图像上是不变的,只有这样,在能得到在不同的图像上进行相同特征的检测。而harris角点虽然具有一定的不变性,但是这种不变性对于特征的匹配的作用不大。
所以,我们可以为每一个特征设计一个描述符,这个描述符有两个作用
- 不变性: 即使图像被变换,描述符也不应该改变
- 区分力: 每一个点的描述符应该是高度唯一的
简单的特征描述符
假设我们将以特征为中心的5×5的窗口的所有像素保存下载,这样就可以将这个5×5的窗口当作一个特征描述符(只有平移不变形)
因为对于不同的特征,他周围的像素只有极小的可能是相同的,所以,我们完全在两个图像中通过这个5×5的窗口来匹配,如果,这个5×5的窗口是相同的,则意味着,这是一个相同的特征
但是显而易见,这个简单的特征描述符仅具有平移不变形。
MOFS特征描述符
Brown发表的一篇论文Multi-Image Matching using Multi-Scale Oriented Patches有提到一种特征描述符
这种描述符对于旋转和投影有尺度不变性。
MOFS特征描述符将特征点周围40×40像素区域子采样得到一个8×8的定向图像块。
我们根据特征点的梯度方向,将图片旋转至特征点的梯度方向水平,保证旋转不变性,
之后,我们进行子采样得到一个8×8的矩阵。

之后我们将这个8×8的图像规范化为一个零均值和单位方差。这将保持仿射不变性
class MOPSFeatureDescriptor(FeatureDescriptor):
def describeFeatures(self, image, keypoints):
image = image.astype(np.float32)
image /= 255.
windowSize = 8
desc = np.zeros((len(keypoints), windowSize * windowSize))
grayImage = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
grayImage = ndimage.gaussian_filter(grayImage, 0.5)
for i, f in enumerate(keypoints):
transMx = np.zeros((2, 3))
angle = (np.pi/180)*f.angle
tran1 = np.array([
[1, 0, -f.pt[0]],
[0, 1, -f.pt[1]],
[0, 0, 1]
])
rot = np.array([
[math.cos(angle), -math.sin(angle), 0],
[math.sin(angle), math.cos(angle), 0],
[0, 0, 1]
])
scal = np.array([
[0.2, 0, 0],
[0, 0.2, 0],
[0, 0, 1]
])
tran2 = np.array([
[1, 0, 4].
[0, 1, 4],
[0, 0, 1]
])
transMx = np.dot(np.dot(np.dot(tran2,scal),rot), tran1)
transMx = transMx[:2, [0, 1, 3]]
destImage = cv2.warpAffine(grayImage, transMx,
(windowSize, windowSize), flags=cv2.INTER_LINEAR)
# 归一化
u = np.mean(destImage)
sigma = np.std(destImage)
normed = ((destImage-u)/sigma) if sigma**2 >= 1e-10 else np.zeros(np.shape(destImage))
desc[i] = normed.flatten()
return desc
图像匹配
当我们得到两个图像的特征描述符,我们就需要确定两个图像中所提取角点是否一致,我们就需要提供一个有效的算法来判断两者是否一致

为了判断这两个角点是否为同一个,我们简单的先提供两种方法
SSD匹配
我们将所有特征描述符两两计算欧式距离平方。我们选取其中相差最小的结果,认为他们是匹配的。
也就是说,我们为了判断一个特征点是否在另一个图片中存在,我们就将这个图片中的特征描述符和另一个图片的所有特征描述符进行计算欧式距离平方,选取其中最小的一个,则认为他与这个特征描述符是同一个角点。
最后计算所有的特征描述符后,进行阈值检测,如果某两个特征描述符的欧式距离平方过大,我们就将其抛弃。
比率匹配
比率匹配的介绍通过在MOPS论文中出现,

在SSD匹配时,我们只选取了最小的那个。而在比率匹配中,我们选取了最好f2的和次好的f2’的两个特征,然后求比值。如果比值在某个阈值之内,则保留。
class SSDFeatureMatcher(FeatureMatcher):
def matchFeatures(self, desc1, desc2):
matches = []
# feature count = n
assert desc1.ndim == 2
# feature count = m
assert desc2.ndim == 2
# the two features should have the type
assert desc1.shape[1] == desc2.shape[1]
if desc1.shape[0] == 0 or desc2.shape[0] == 0:
return []
SSD = scipy.spatial.distance.cdist(desc1, desc2)
SSD_max = np.min(SSD, axis=1)
index = np.argmin(SSD, axis=1)
for i in range(len(index)):
M = cv2.DMatch(_queryIdx=i, _trainIdx=index[i], _distance=SSD_max[i])
matches.append(M)
return matches
class RatioFeatureMatcher(FeatureMatcher):
def matchFeatures(self, desc1, desc2):
matches = []
# feature count = n
assert desc1.ndim == 2
# feature count = m
assert desc2.ndim == 2
# the two features should have the type
assert desc1.shape[1] == desc2.shape[1]
if desc1.shape[0] == 0 or desc2.shape[0] == 0:
return []
dists = spatial.distance.cdist(desc1, desc2)
index = np.argmin(dists, axis=1)
for i in range(len(index)):
distsi = dists[i]
bestMatch = index[i]
bestDist = np.min(distsi)
#alter distsi to change the previous min to a really big number
distsi[index[i]] = float('inf')
secondBestMatch = np.argmin(distsi)
secondBestDist = np.min(distsi)
ratioDist = bestDist/secondBestDist
m = cv2.DMatch(_queryIdx = i, _trainIdx = index[i], _distance = ratioDist)
matches.append(m)
return matches
总结
现在我们已经了解了角点检测和特征描述符的知识,至此,我们就学会了完整的进行图像间匹配的方法。
对于给出的两个图像,如果我们需要判断两个图像是否有相似的地方,我们应当按以下顺序进行
- 角点检测
- 构建特征描述符
- 选择匹配算法进行匹配
这是基本的过程,在很多算法中如SIFT,SUFT都有自己的完整的算法,这里所提到的内容只是建立一个概念,实际上他们的效果并不是很好。我们在更多的时候应该选择更加高效的算法。
Opencv实现
为了在Opencv中应用这些东西,我们需要了解一下Opencv提供的一些数据类型, 为了调用Opencv中的函数以更好的可视化的了解这些算法,甚至帮助你设计自己的算法。
我以ORB算法来进行下面的操作,因为手动去实现上述的内容并一一调用过于麻烦了。
KeyPoint
Opencv提供了Keypoint数据类型来存储角点信息。
img = cv.imread('resources/triangle1.jpg')
orb = cv.ORB_create(123)
keypoints, feature = orb.detectAndCompute(img,None)
print(type(keypoints))
print(keypoints)
print(type(feature))
print(feature[:5])
# Return
<class 'list'>
[<KeyPoint 0x7fb98a65f030>, <KeyPoint 0x7fb989f5c150>, <KeyPoint 0x7fb989f5c090>, <KeyPoint 0x7fb989f5c0c0>, <KeyPoint 0x7fb989f5c0f0>, <KeyPoint 0x7fb989f5c120>, <KeyPoint 0x7fb989f5c1b0>, <KeyPoint 0x7fb989f5c1e0>, <KeyPoint 0x7fb989f5c210>, <KeyPoint 0x7fb989f5c240>, <KeyPoint 0x7fb989f5c270>, <KeyPoint 0x7fb989f5c2a0>, <KeyPoint 0x7fb989f5c2d0>]
<class 'numpy.ndarray'>
[[116 48 185 97 160 76 81 16 98 248 166 8 23 23 65 58 133 84
124 24 9 96 248 0 203 233 37 116 192 128 70 51]
[104 48 185 100 32 76 81 16 98 232 38 8 159 23 64 114 132 84
124 8 1 96 185 0 203 217 37 48 64 128 71 115]
[ 96 48 185 100 8 76 81 16 98 232 38 8 214 55 64 50 128 84
108 8 9 96 240 0 203 185 5 16 64 96 70 115]
[104 48 57 96 0 77 81 16 98 232 164 8 151 23 64 50 133 212
124 24 9 96 240 0 203 201 37 48 64 128 70 51]
[104 48 185 100 32 77 81 16 99 232 38 8 150 23 64 50 132 84
124 24 1 96 185 0 203 217 37 48 64 128 70 51]]
可以看到,orb.detectAndCompute返回一个特征点集和一个特征描述符集,需要注意的是,角点的索引和特征描述符的索引应当是一一对应的。特征描述符集就是一个ndarry类型,而特征点集是一个列表,列表中为KeyPoint类型
cv.KeyPoint ( pt, size, angle = -1, response = 0, octave = 0, class_id = -1 )
参数:
- pt: 特征点的坐标,x和y
- size: 有意义的特征点邻域的直径
- angle: 角点的方向, 旋转不变性
- response: 选择最强关键点的响应。可用于进一步的排序或二次采样(不清楚作用)
- octave: 提取特征点的金子塔的层数(SIFT之类的算法)
- class_id: 对象类(如果关键点需要由它们所属的对象聚类)
对于这些参数,对于不同的角点检测方法需要不同的参数,比如Harris角点检测,我们不需要Octave参数,就可以无视他
key = keypoints[0]
print(key)
print(key.pt)
print(key.angle)
print(key.response)
print(key.octave)
print(key.size)
# Return
<KeyPoint 0x7f13952e1c60>
(92.0, 48.0)
96.48876190185547
0.0007334801484830678
0
31.0
画出角点
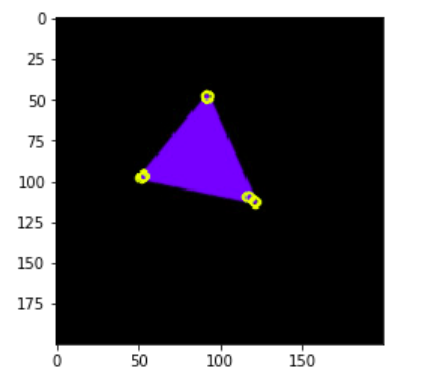
不妨再掌握一个函数,用于画出图片中的角点。Opencv提供了一个函数cv.drawKeypoints()可以画出图像中的角点
cv.drawKeypoints(image, keypoints, outImage, color, flags)
参数:
- image: 原图
- keypoints: 原图的特征点
- outimage: 输出图像
- color: 特征点的颜色
- flags:标记设置绘图功能,官网。
outimage = cv.drawKeypoints(img, keypoints, None, [255, 255, 0])
plt.imshow(outimage), plt.show()
DMatch
在了解DMatch数据类型时,先了解一下Opencv提供的匹配方法。
Opencv提供了两种计算匹配的类,第一个是BFMatcher,第二个是FLANNMatcher
BFMatcher
BFMatcher是一个简单的暴力匹配器,使用一些距离计算将其与第二组中的所有特征匹配,并返回最接近的一个,SSD就是一个经典的暴力匹配方式。
在Python中创建BFMatcher匹配器,使用cv.BFMatcher_create()函数即可。
retval = cv.BFMatcher_create(normType, crossCheck )
参数:
- normType:
NORM_L1,NORM_L2,NORM_HAMMING,NORM_HAMMING2中的一个。对于SIFT和SURF描述述符,L1和L2规范是更好的选择,NORM_HAMMING应该与ORB,BRISK和Brief一起使用,当WTA_K == 3或4时(参考ORB描述符),NORM_HAMMING2应该与ORB一起使用。官网. - crossCheck :如果为false,则为每个查询描述符找到k个最近的邻居时,这将是默认的BFMatcher行为。如果crossCheck == true,则k = 1的knnMatch()方法将仅返回对(i,j),这样对于第i个查询描述符,匹配器集合中的第j个描述符是最近的,反之亦然.
当我们得到匹配器之后,我们就可以进行匹配了。我们有两个函数
matcher.match(des1, des2) # 返回最佳匹配
matcher.knnMatch(des1, des2, k) # 返回前K佳匹配
我们可以通过knnMatch来实现Ratio匹配
def test():
img1 = cv.imread('resources/triangle1.jpg')
img1 = cv.cvtColor(img1, cv.COLOR_BGR2GRAY)
keypoints1, descriptors1 = ORB.detectAndCompute(img1, None)
img2 = cv.imread('resources/triangle2.jpg')
img2 = cv.cvtColor(img2, cv.COLOR_BGR2GRAY)
keypoints2, descriptors2 = ORB.detectAndCompute(img2, None)
bf = cv.BFMatcher()
matches = bf.knnMatch(descriptors1, descriptors2, k=2) # 返回最佳匹配和次佳匹配
good = []
for m, n in matches:
if m.distance / n.distance < 0.75:
good.append(m) # 比率小于某一个阈值,则认为是匹配的
FlannBasedMatcher
FLANN表示近似最近邻的快速库。它包含一组算法,这些算法针对大型数据集中的快速最近邻搜索和高维特征进行了优化。对于大型数据集,FlannBasedMatcher的运行速度比BFMatcher快。
我们创建FlannBasedMatcher需要传递两个字典,这些字典指定要使用的算法及其相关参数等。
第一个字典是IndexParams。对于各种算法,要传递的信息在FLANN文档中有说明, Opencv官网
第二个字典是SearchParams。它指定索引中的树应递归遍历的次数。较高的值可提供更好的精度,但也需要更多时间。
对于SIFI,SUFT算法,你可以这样操作:
FLANN_INDEX_KTREE=1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
对于ORB算法,你可以这样操作:
FLANN_INDEX_LSH = 6
index_params= dict(algorithm = FLANN_INDEX_LSH,
table_number = 6, # 12
key_size = 12, # 20
multi_probe_level = 1) #2
search_params = dict(checks=50) # or pass empty dictionary
flann = cv.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
如果你想要了解细节,请参考官网
DMatch
对于两种匹配方法,都是基于DMatch的, Matcher.match()返回是DMatch数据类型的列表
print(matches)
# Return
[<DMatch 0x7f1827098390>, <DMatch 0x7f18271627d0>, <DMatch 0x7f18271628b0>, <DMatch 0x7f18271624b0>, <DMatch 0x7f1827162070>, <DMatch 0x7f1827162c70>]
cv.DMatch( _queryIdx, _trainIdx, _distance)
参数:
- _queryIdx: 第一个图的特征点的索引, 也是特征描述符的索引
- _trainIdx: 第二个图的特征点的索引,也是特征描述符的索引
- _distance: 两个图的特征点的匹配情况,越小越好
明白了这些,我们甚至可以重新构造Ratio特征匹配方式
def test():
img1 = cv.imread('resources/triangle1.jpg')
img1 = cv.cvtColor(img1, cv.COLOR_BGR2GRAY)
keypoints1, descriptors1 = ORB.detectAndCompute(img1, None)
img2 = cv.imread('resources/triangle2.jpg')
img2 = cv.cvtColor(img2, cv.COLOR_BGR2GRAY)
keypoints2, descriptors2 = ORB.detectAndCompute(img2, None)
bf = cv.BFMatcher()
matches = bf.knnMatch(descriptors1, descriptors2, k=2) # 返回最佳匹配和次佳匹配
Ratio = []
for m, n in matches:
r = cv.DMatch(_queryIdx = m.queryIdx, _trainIdx = m.trainIdx, _distance = m.distance/n.distance)
Ratio.append(m)
画出匹配关系
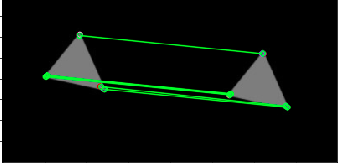
就如同可以使用cv.drawKeypoints画出角点,我们也可以使用cv.drawMatches()画出匹配模式, 同时他也提供了cv.drawMatchesKnn()
outImg = cv.drawMatches( img1, keypoints1, img2, keypoints2, matches1to2, outImg, matchColor, singlePointColor, matchesMask, flags)
参数:
- img1: 第一张图
- keypoints1: 第一张图的角点
- img2: 第二张图
- keypoints2: 第二张图的角点
- matches1to2:第一张图的特征点匹配第二张图的特征点,这意味着keypoints1 [i]在keypoints2 [matches [i]]中具有一个对应点。
- outImg:输出图像。
- matchColor: 匹配项的颜色(线和连接的关键点), 若matchColor==Scalar::all(-1),颜色随机.
- singlePointColor: 单个关键点(圆圈)的颜色,这意味着关键点没有匹配项。如果singlePointColor == Scalar :: all(-1),颜色随机。
- matchesMask: Mask聚顶那些匹配项被画出,如果Mask为空,则所有匹配项都被画出
- flags:标记设置绘图功能。可能的标志位值由
DrawMatchesFlags定义。DrawMatchesFlags
img1 = cv.imread('resources/triangle1.jpg')
img1 = cv.cvtColor(img1, cv.COLOR_BGR2GRAY)
keypoints1, descriptors1 = orb.detectAndCompute(img1, None)
img2 = cv.imread('resources/triangle2.jpg')
img2 = cv.cvtColor(img2, cv.COLOR_BGR2GRAY)
keypoints2, descriptors2 = orb.detectAndCompute(img2, None)
bf = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True)
matches = bf.match(descriptors1, descriptors2)
outImg = cv.drawMatches(img1,keypoints1,img2,keypoints2,matches,None,matchColor=(0,255,0),flags=cv.DRAW_MATCHES_FLAGS_DEFAULT)
plt.imshow(outImg),plt.show()